
Quick sort with median-of-medians algorithm
The median-of-medians algorithm is a deterministic linear-time selection algorithm.
Using this algorithm, we can improve quick sort algorithm!
1
2
3
4
5
6
7
8
9
10
11
12
13
import numpy as np
from random import seed
import copy, random
import time
def logging_time(original_fn):
def wrapper_fn(*args, **kwargs):
start_time = time.time()
result = original_fn(*args, **kwargs)
elapsed_time = (time.time() - start_time) * 1e3
print("WorkingTime[{}]: {:.5f} ms".format(original_fn.__name__, elapsed_time))
return result
return wrapper_fn
Selection Algorithm
Before we will learn out quick sort, let’s look at quick selection algorithm.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# QuickSelect: pick k th smallest element.
# assume that array values should be distinct.
# it takses average O(n), worst O(n^2) time.
# This is because pivot determines reculsive call deviding ratio!
@logging_time
def QuickSelectRandom(a, p, r, k):
""" call randomized quick select algorithm """
return QuickSelect(a, p, r, k)
def QuickSelect(a, p, r, k):
if p == r:
return a[p]
else:
i = np.random.randint(p, r+1)
a[r], a[i] = a[i], a[r]
# randomized partition with pivot as a[r]
i = p - 1
for j in range(p, r):
if a[j] <= a[r]:
i += 1
a[i], a[j] = a[j], a[i]
a[i+1], a[r] = a[r], a[i+1]
q = i+1
# divide and conquer for QuickSelect
i = q - p + 1
if k <= i:
return QuickSelect(a, p, q, k)
else:
return QuickSelect(a, q+1, r, k-i)
1
2
3
4
5
a = random.sample(range(1, 100), 10)
k = 3
print(a)
out = QuickSelectRandom(a, 0, len(a)-1, k)
print("{}-th smallest element: {}".format(k, out))
1
2
3
4
[10, 96, 49, 61, 92, 33, 90, 28, 25, 77]
WorkingTime[QuickSelectRandom]: 0.16379 ms
3-th smallest element: 28
Average Time Complexity Analysis
\(T(n) = T(n/2) + O(n) = O(n)\)
However, worst case time complexity is $O(n^2)$
This is because pivot determines dividing ratio.
Therefore, in a worst case,
\(T(n) = T(n-1) + O(n) = O(n^2)\)
Better Algorithm - Use median of medians
[PseudoCode] kthSmallest using finding Median of Median and tranformed QickSelect algorithm link
kthSmallest(arr[0..n-1], k)
1) Divide arr[] into ⌈n/5⌉ groups where size of each group is 5
except possibly the last group which may have less than 5 elements.
2) Sort the above created ⌈n/5⌉ groups and find median
of all groups. Create an auxiliary array 'median[]' and store medians
of all ⌈n/5⌉ groups in this median array.
// Recursively call this method to find median of median[0..⌈n/5⌉-1]
3) medOfMed = kthSmallest(median[0..⌈n/5⌉-1], ⌈n/10⌉)
4) Partition arr[] around medOfMed and obtain its position.
pos = partition(arr, n, medOfMed)
5) If pos == k return medOfMed
6) If pos > k return kthSmallest(arr[l..pos-1], k)
7) If pos < k return kthSmallest(arr[pos+1..r], k-pos+l-1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
""" helper functions """
# assume that r-p+1 <= 5
def findMedian(a, p, r):
L = []
for i in range(p, r+1):
L.append(a[i])
L.sort()
return L[(r-p+1)//2]
def partition(a, p, r, x):
# we should find out medOfmed's index i value in the a[p..r]
# swap a[i], a[r] in order to make a[r] as a pivot
for i in range(p, r+1):
if a[i] == x:
a[i], a[r] = a[r], a[i]
break
i = p - 1
for j in range(p, r):
if a[j] <= a[r]:
i += 1
a[i], a[j] = a[j], a[i]
a[i+1], a[r] = a[r], a[i+1]
return i+1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
@logging_time
def QuickSelectMedians(a, p, r, k):
""" call quick select with median of medians algorithm. """
return KthSmallest(a, p, r, k)
def KthSmallest(a, p, r, k):
# divide A into floor(n/5) groups
# create median array with size floor(n/5)
n = r - p + 1
median = []
i = 0
while i < n//5:
# 5 element can be assigned for each group
median.append(findMedian(a, p+5*i, p+5*i+4))
i += 1
# if last group has n%5 (remainder) elements
if i*5 < n:
median.append(findMedian(a, p+5*i, p+5*i+(n%5-1)))
i += 1
# so, at this time i value means floor(n/5)
if i == 1:
# if median has only one elements, the medOfmed should be median[0]
medOfmed = median[i-1]
else:
# reculsively medOfmed can be found.
# Because median array is generated each recursion, i value should be shrunk more and more
medOfmed = KthSmallest(median, 0, i-1, i//2)
# at this bottom line, medOfmed can be determined
# if we use the pivot as medofmed value, the number of sorted elements can be 3(floor(n/5)/2 - 2)
q = partition(a, p, r, medOfmed)
# i value means medOfmed's rank in a[...] array
i = q - p + 1
if i == k:
# if partitioned pivot is the kth Smallest element
return a[q]
elif i > k:
return KthSmallest(a, p, q-1, k)
else:
return KthSmallest(a, q+1, r, k-i)
1
2
3
4
5
6
7
8
9
10
11
12
13
for SEED in range(5):
print("seed = {} {}".format(SEED, '='*50))
seed(SEED)
np.random.seed(SEED)
n, k = 100, 20
a = list(np.random.randint(-1000, 1000, size=n))
test = copy.deepcopy(a)
ans1 = QuickSelectRandom(test, 0, n-1, k)
print("> 1. worst case O(n^2), average O(n) select algorithm's output: {}".format(ans1))
test = copy.deepcopy(a)
ans2 = QuickSelectMedians(test, 0, n-1, k)
print("> 2. worst case O(n) select algorithm's output: {:>20}".format(ans2))
assert ans1 == ans2 == sorted(test)[k-1], "Fail"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
seed = 0 ==================================================
WorkingTime[QuickSelectRandom]: 0.07701 ms
> 1. worst case O(n^2), average O(n) select algorithm's output: -612
WorkingTime[QuickSelectMedians]: 0.12517 ms
> 2. worst case O(n) select algorithm's output: -612
seed = 1 ==================================================
WorkingTime[QuickSelectRandom]: 0.10681 ms
> 1. worst case O(n^2), average O(n) select algorithm's output: -492
WorkingTime[QuickSelectMedians]: 0.13685 ms
> 2. worst case O(n) select algorithm's output: -492
seed = 2 ==================================================
WorkingTime[QuickSelectRandom]: 0.09274 ms
> 1. worst case O(n^2), average O(n) select algorithm's output: -546
WorkingTime[QuickSelectMedians]: 0.15426 ms
> 2. worst case O(n) select algorithm's output: -546
seed = 3 ==================================================
WorkingTime[QuickSelectRandom]: 0.09656 ms
> 1. worst case O(n^2), average O(n) select algorithm's output: -481
WorkingTime[QuickSelectMedians]: 0.13661 ms
> 2. worst case O(n) select algorithm's output: -481
seed = 4 ==================================================
WorkingTime[QuickSelectRandom]: 0.10538 ms
> 1. worst case O(n^2), average O(n) select algorithm's output: -640
WorkingTime[QuickSelectMedians]: 0.15450 ms
> 2. worst case O(n) select algorithm's output: -640
Time Complexity Analysis
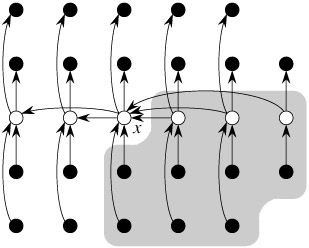
Bottom left: These items may be bigger (or smaller!) than the median
Top right: These items may be bigger (or smaller!) than the median
Bottom right: Every item in this quadrant is strictly greater than the median
$T(n/5)$ means recursive call when finding medOfmed value
when we use medOfmed as a pivot, after partitioning,
assure that at least $3((n/5)/2 - 2)$ elements must be less or larger than medOfmed.
(where, -2 term means except for medOfmed group and last group.)
Therefore, next recursive call for KthSmallest selcect array size is $n - 3((n/5)/2 - 2) = 7n/10 + 6$
The master theorem can be used to show that this recurrence equals $O(n)$.
Better Quick Sort Algorithm
If we find out medOfmed in $O(n)$ time, and the medOfmed as a pivot.
At worst case, Quick Sort time complexity $O(nlogn)$
1
2
3
4
5
6
7
8
9
10
11
12
13
@logging_time
def Medians(a, p, r):
""" call quick select with median of medians algorithm. """
return QuickSort(a, p, r)
def QuickSort(a, p, r):
if p >= r:
return
med = KthSmallest(a, p, r, (r-p+1)//2)
q = partition(a, p, r, med)
QuickSort(a, p, q-1)
QuickSort(a, q+1, r)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@logging_time
def Random(a, p, r):
""" call quick select with median of medians algorithm. """
return quick(a, p, r)
def quick(a, p, r):
if p < r : # p >= r 이 되면 종료
i = np.random.randint(p, r+1)
a[r], a[i] = a[i], a[r]
# randomized partition with pivot as a[r]
i = p - 1
for j in range(p, r):
if a[j] <= a[r]:
i += 1
a[i], a[j] = a[j], a[i]
a[i+1], a[r] = a[r], a[i+1]
q = i+1
quick(a, p, q -1)
quick(a, q + 1, r)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from random import seed
import numpy as np
import copy
for SEED in range(5):
print("seed = {} {}".format(SEED, '='*50))
seed(SEED)
np.random.seed(SEED)
n = 10000
a = list(np.random.randint(-100000, 100000, size=n))
# a = random.sample(range(1, 1000000), n) # generate distinct values
test1 = copy.deepcopy(a)
Medians(test1, 0, n-1)
test2 = copy.deepcopy(a)
Random(test2, 0, n-1)
# print(test)
assert test1 == test2 == sorted(copy.deepcopy(a)), "sanity check: failed."
# print(test)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
seed = 0 ==================================================
WorkingTime[Medians]: 451.17879 ms
WorkingTime[Random]: 136.27052 ms
seed = 1 ==================================================
WorkingTime[Medians]: 327.23093 ms
WorkingTime[Random]: 72.36290 ms
seed = 2 ==================================================
WorkingTime[Medians]: 289.16669 ms
WorkingTime[Random]: 76.33543 ms
seed = 3 ==================================================
WorkingTime[Medians]: 219.12909 ms
WorkingTime[Random]: 96.14420 ms
seed = 4 ==================================================
WorkingTime[Medians]: 398.00739 ms
WorkingTime[Random]: 206.22993 ms
Report
Although quick sort with median of medians is faster mathmatically,
overhead makes the algorithm to be slow than randomized quicksort algorithm.

Leave a comment