
In [1]:
1
2
3
4
5
import random, sys
import numpy as np
import matplotlib.pyplot as plt
sys.path.append("/home/swyoo/algorithm")
from utils.verbose import logging_time, printProgressBar
In [2]:
1
2
3
# toy examples
points = [[3, 3], [5, -1], [-2, 4]]
K = 2
973. K_Closest_Points
Naive
sort by distance
In [3]:
1
2
3
4
@logging_time
def naive(points, K):
dist = lambda i: points[i][0]**2 + points[i][1]**2
return sorted(points, key=lambda x: x[0]**2 + x[1]**2)[:K]
In [4]:
1
naive(points, K, verbose=True)
1
2
WorkingTime[naive]: 0.00763 ms
1
[[3, 3], [-2, 4]]
Quick Select Approach
If we use quick select approach, the average time will be $O(n)$ like quick select.
if you want to know about details that describes why using quick select leads to $O(n)$ (averaging time),
please visit this url.
You can run about more efficient approach to use quick select.
In [5]:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class Solution(object):
@logging_time
def kClosest(self, points, K):
"""
:type points: List[List[int]]
:type K: int
:rtype: List[List[int]]
"""
dist = lambda i: points[i][0] ** 2 + points[i][1] ** 2
def partition(s, e):
""" partition by randomized pivot distance with origin. """
i = random.randint(s, e)
points[e], points[i] = points[i], points[e]
i = s - 1
for j in range(s, e):
if dist(j) < dist(e):
i += 1
points[i], points[j] = points[j], points[i]
points[i + 1], points[e] = points[e], points[i + 1]
return i + 1
def select(s, e, K):
if s >= e: return
q = partition(s, e)
if q - s + 1 < K: select(q + 1, e, K - (q - s + 1))
elif q - s + 1 > K: select(s, q - 1, K)
else: return
select(0, len(points) - 1, K)
return points[:K] # return top K points
sol = Solution()
In [6]:
1
sol.kClosest(points, K, verbose=True)
1
2
WorkingTime[kClosest]: 0.02193 ms
1
[[3, 3], [-2, 4]]
Analysis
In [8]:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
SEED = 0
np.random.seed(seed=SEED)
random.seed(SEED)
num_exp = 10
t1, t2 = [0] * num_exp, [0] * num_exp
sizes = list(np.linspace(start=1000, stop=1e6, num=num_exp))
for i, size in enumerate(sizes):
size = int(size)
K = random.randint(1, size // 3)
""" generate 2D points within 10*size square. """
points = [np.random.randint(-5 * size, 5 * size, size=2).tolist() for i in range(size)]
ans1, t1[i] = naive(points, K)
ans2, t2[i] = sol.kClosest(points, K)
assert False not in list(np.sum(np.array(ans1), axis=0) == np.sum(np.array(ans2), axis=0)), "not matched"
printProgressBar(iteration=i+1, total=num_exp, msg='experiments ...', length=50)
1
|██████████████████████████████████████████████████| 100.0 % - experiments ...
In [9]:
1
2
3
4
5
6
7
8
9
plt.style.use(style="dark_background")
plt.grid(linestyle='--')
plt.xlabel('size')
plt.ylabel('time')
plt.title("Time Complexity Analysis")
plt.plot(sizes, t1, 'o-r', label="naive")
plt.plot(sizes, t2, '*-g', label="divide conquer")
plt.legend(loc='upper left')
plt.show()
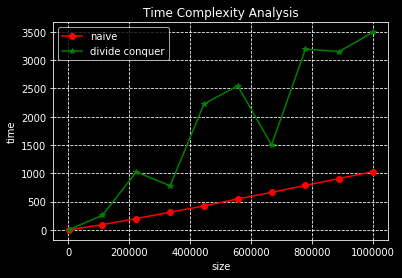
Report
이론상으로는 divide and conquer가 더 좋지만, divide and conquer를 recursive version으로 구현했기 때문에,
overhead가 커서 sorted built-in 함수에 의한 sort가 더 빨랐다.

Leave a comment